正規表達式是一個範本字串,可以用來進行字串對比,為一種小型的字串比對語言。其範本字串是使用英文字母、數字和一些特殊字元所組成,裡面包含了以下字元,下方列出一些常見的正規表達式:
| 表示法 | 意義 |
|---|---|
| [abc] | 包含英文字母 a、b 或 c |
| [a-zA-Z] | 任何大小寫的英文字母 |
| [^abc] | 除了a、b和c以外的任何字母 |
| [0-9] | 數字0-9 |
| 表示法 | 意義 |
|---|---|
| ^ | 第1個字元開始比對 |
| $ | 字串最後須符合範本字串 |
| . | 代表任何一個字元 |
| {n} | 出現n次 |
| 表示法 | 意義 |
|---|---|
| \n | 換新行符號 |
| \r | 換行並移到最前端 |
| \t | Tab鍵 |
搜尋文字內容:在FJU_p4.html中找出「醫院資訊系統」的文字段落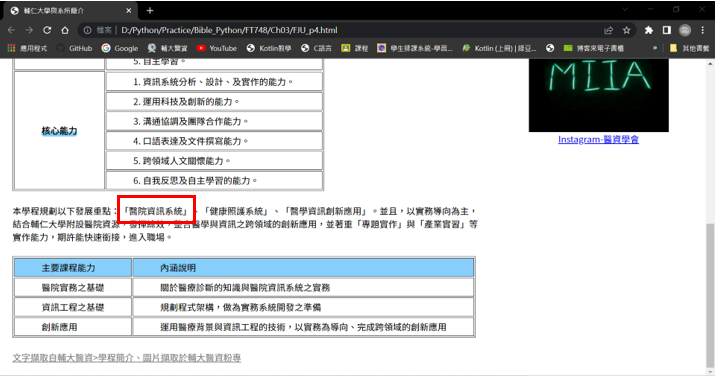
import re
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 使用正規運算式搜尋文字內容
regexp = re.compile("「醫院資訊系統」")
tag_str = soup.find(text=regexp)
print(tag_str)
regexp = re.compile("\「+\w+\」")
tag_list = soup.find_all(text=regexp)
print(tag_list)

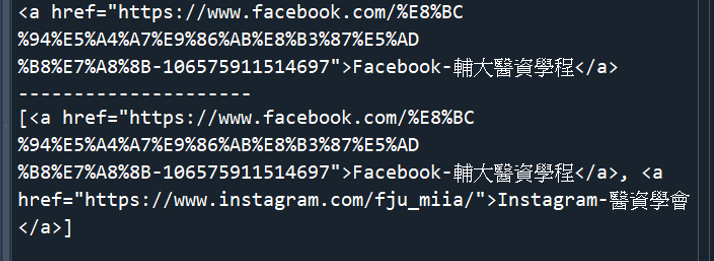
搜尋URL網址:在FJU_p4.html中找出粉絲專頁的FB、IG連結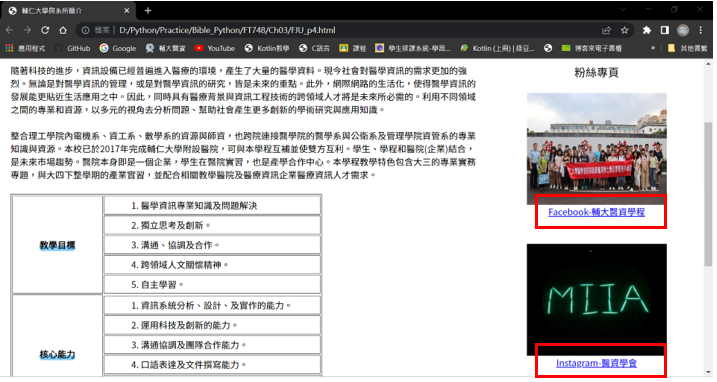
import re
from bs4 import BeautifulSoup
with open("FJU_p4.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 使用正規運算式搜尋URL網址
url_regexp = re.compile("^https:")
tag_href = soup.find("a", href=url_regexp)
print(tag_href)
print("---------------------")
tag_list = soup.find_all("a", href=url_regexp)
print(tag_list)